
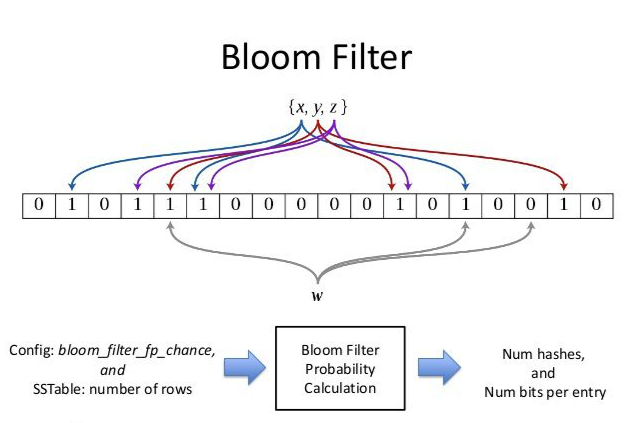
布隆过滤器(Bloom Filter)是一种空间效率极高的概率型数据结构,由Burton Howard Bloom于1970年提出。最核心的作用是快速判断一个元素是否可能存在于一个集合中。
一、布隆过滤器基础理论
1.1 数据结构原理
布隆过滤器由两部分组成:
- 一个长度为m的位数组(Bit Array)
- k个不同的哈希函数
当添加元素时,会使用k个哈希函数计算出k个哈希值,并将位数组中对应的位置设为1。查询时,同样计算k个哈希值,只有所有对应位都为1时才认为元素可能存在(可能有误判)。
1.2 特性分析
优点:
- 空间效率极高,远超过哈希表
- 查询时间复杂度为O(k),与元素数量无关
- 添加元素时间也是O(k)
缺点:
- 存在误判率(False Positive)
- 无法删除元素(除非使用变种如Counting Bloom Filter)
1.3 参数设计
布隆过滤器的性能取决于三个参数:
- n:预期元素数量
- m:位数组长度
- k:哈希函数数量
最优参数关系:
- m = – (n * ln p) / (ln 2)^2
- k = (m / n) * ln 2
其中p是期望的误判率
二、bits-and-blooms/bloom/v3架构解析
2.1 模块组成
该库主要由以下核心组件构成:
- BloomFilter结构体:主过滤器实现
- 哈希函数模块:优化的MurmurHash3实现
- bitset:高效的位集合操作
- 参数估算模块:自动计算最优m和k
2.2 核心数据结构
type BloomFilter struct {
m uint // 位数组长度
k uint // 哈希函数数量
b *bitset.BitSet // 位集合实现
}
2.3 哈希函数实现
该库使用自行实现的MurmurHash3变种,关键优化点包括:
- 完全避免堆内存分配
- 使用unsafe直接操作字节切片
- 内联关键位操作
- 一次计算可生成4个哈希值
func (d *digest128) sum256(data []byte) (hash1, hash2, hash3, hash4 uint64) {
// 优化的哈希计算过程
// We always start from zero.
d.h1, d.h2 = 0, 0
// Process as many bytes as possible.
d.bmix(data)
// We have enough to compute the first two 64-bit numbers
length := uint(len(data))
tail_length := length % block_size
tail := data[length-tail_length:]
hash1, hash2 = d.sum128(false, length, tail)
// Next we want to 'virtually' append 1 to the input, but,
// we do not want to append to an actual array!!!
if tail_length+1 == block_size {
// We are left with no tail!!!
word1 := binary.LittleEndian.Uint64(tail[:8])
word2 := uint64(binary.LittleEndian.Uint32(tail[8 : 8+4]))
word2 = word2 | (uint64(tail[12]) << 32) | (uint64(tail[13]) << 40) | (uint64(tail[14]) << 48)
// We append 1.
word2 = word2 | (uint64(1) << 56)
// We process the resulting 2 words.
d.bmix_words(word1, word2)
tail := data[length:] // empty slice, deliberate.
hash3, hash4 = d.sum128(false, length+1, tail)
} else {
// We still have a tail (fewer than 15 bytes) but we
// need to append '1' to it.
hash3, hash4 = d.sum128(true, length+1, tail)
}
return hash1, hash2, hash3, hash4
}
三、关键操作实现解析
3.1 初始化过滤器
// 直接指定参数
filter := bloom.New(m, k)
// 自动估算参数
filter := bloom.NewWithEstimates(n, fp)
参数估算算法:
func EstimateParameters(n uint, p float64) (m uint, k uint) {
m = uint(math.Ceil(-1 * float64(n) * math.Log(p) / math.Pow(math.Log(2), 2)))
k = uint(math.Ceil(math.Log(2) * float64(m) / float64(n)))
return
}
3.2 添加元素
func (f *BloomFilter) Add(data []byte) *BloomFilter {
h := baseHashes(data) // 获取4个基础哈希值
for i := uint(0); i < f.k; i++ {
// 计算k个位置并设置位
f.b.Set(f.location(h, i))
}
return f
}
位置计算算法:
func location(h [4]uint64, i uint) uint64 {
ii := uint64(i)
return h[ii%2] + ii*h[2+(((ii+(ii%2))%4)/2)]
}
3.3 查询元素
func (f *BloomFilter) Test(data []byte) bool {
h := baseHashes(data)
for i := uint(0); i < f.k; i++ {
if !f.b.Test(f.location(h, i)) {
return false
}
}
return true
}
3.4 高级操作
- 原子性测试并添加:
func (f *BloomFilter) TestOrAdd(data []byte) bool {
present := true
h := baseHashes(data)
for i := uint(0); i < f.k; i++ {
l := f.location(h, i)
if !f.b.Test(l) {
present = false
f.b.Set(l)
}
}
return present
}
- 合并过滤器:
func (f *BloomFilter) Merge(g *BloomFilter) error {
if f.m != g.m || f.k != g.k {
return errors.New("参数不匹配")
}
f.b.InPlaceUnion(g.b)
return nil
}
3.5 基本用法
package main
import (
"fmt"
"github.com/bits-and-blooms/bloom/v3"
)
func main() {
// 创建一个布隆过滤器,预计包含10000个元素,误判率为0.01%
filter := bloom.NewWithEstimates(10000, 0.0001)
// 添加元素
filter.Add([]byte("hello"))
filter.Add([]byte("world"))
filter.Add([]byte("golang"))
// 测试元素是否存在
fmt.Println("Contains 'hello':", filter.Test([]byte("hello"))) // true
fmt.Println("Contains 'world':", filter.Test([]byte("world"))) // true
fmt.Println("Contains 'golang':", filter.Test([]byte("golang"))) // true
fmt.Println("Contains 'python':", filter.Test([]byte("python"))) // false (可能)
// 获取布隆过滤器的统计信息
fmt.Printf("Filter capacity: %d\n", filter.Cap())
fmt.Printf("Filter K (number of hash functions): %d\n", filter.K())
}
四、性能优化技术
4.1 哈希计算优化
- 使用unsafe.Pointer直接访问字节切片,避免拷贝:
b := (*[16]byte)(unsafe.Pointer(&p[i*block_size]))- 内联关键位操作:
h1 = bits.RotateLeft64(h1, 27)
h1 += h2
h1 = h1 * 5 + 0x52dce729
4.2 内存管理
- 位集合使用紧凑存储
- 避免不必要的内存分配
- 批量操作减少函数调用开销
4.3 并发安全
标准实现不是并发安全的,如需并发使用需要:
- 使用sync.Mutex包装
- 或使用每个goroutine独立的过滤器最后合并
五、实践应用案例
5.1 缓存穿透防护
func getFromCache(key string) ([]byte, error) {
if !bloomFilter.TestString(key) {
return nil, ErrNotExist
}
// 继续查询缓存...
}5.2 爬虫URL去重
func shouldCrawl(url string) bool {
if bloomFilter.TestString(url) {
return false
}
bloomFilter.AddString(url)
return true
}5.3 数据库查询优化
func queryDB(userID string) {
if !filter.TestString(userID) {
return // 肯定不存在
}
// 继续查询数据库...
}六、最佳实践建议
- 参数选择:
- 对于100万元素,1%误判率约需9585059位(1.14MB)和7个哈希函数
- 使用
EstimateParameters自动计算
- 性能调优:
- 对于已知固定大小数据集,可适当增加m减少误判率
- 对于内存敏感场景,可接受稍高误判率减少内存使用
- 错误处理:
- 对于关键业务,布隆过滤器结果应作为前置条件而非最终判断
- 可结合其他数据结构减少误判影响
- 扩展场景:
- 大数据集考虑分片布隆过滤器
- 动态增长数据集考虑Scalable Bloom Filter
